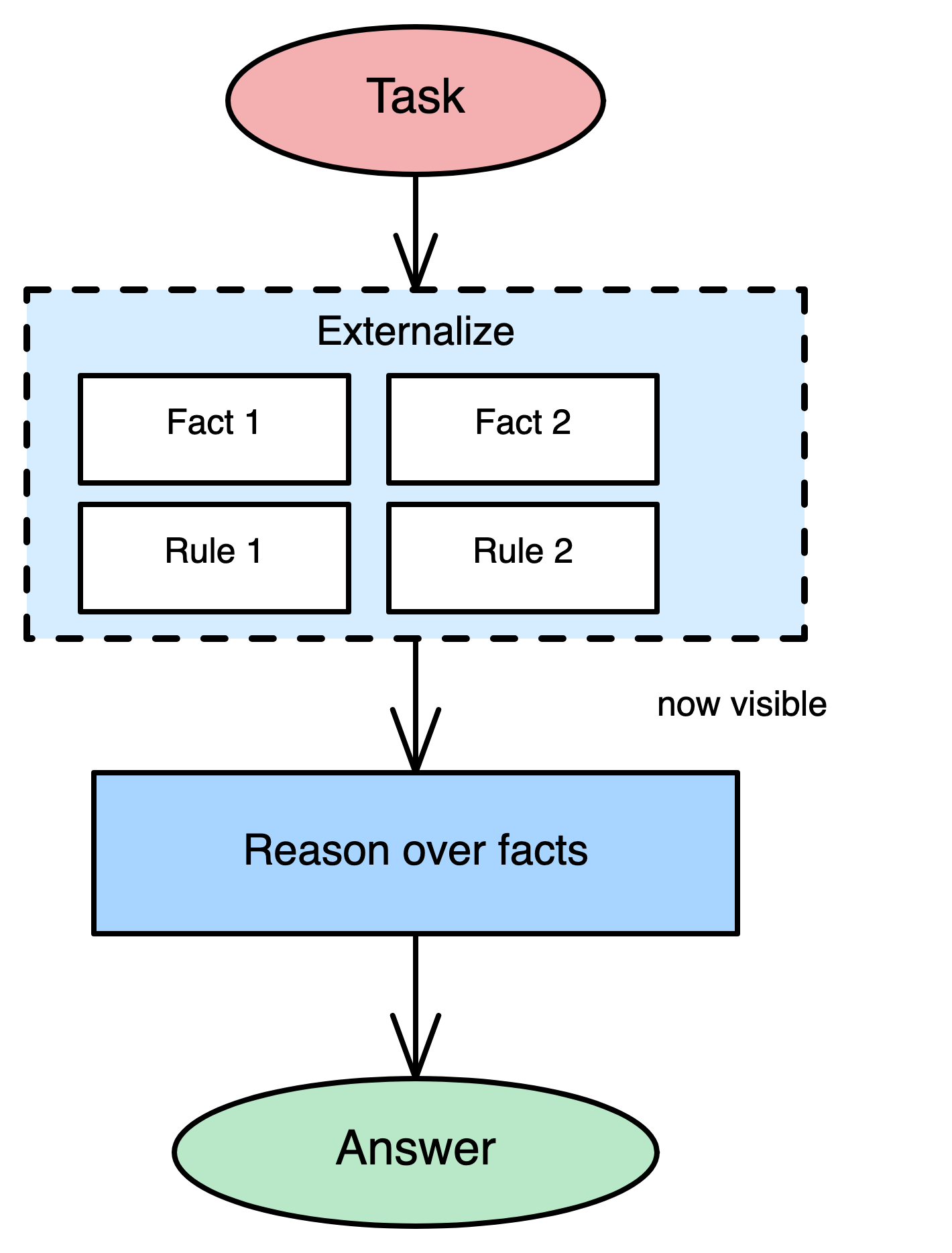
Knowledge Externalization
Requires the model to expose the background knowledge it will rely on before performing the task.
Problem
Models often answer from unstated premises, producing fluent but weakly grounded judgments.
Solution
Require the model to externalize relevant principles/facts first, then bind reasoning to them. Explicit premises in context make the reasoning basis inspectable and more coherent.
Example
One worked example. The book has 2–4 per technique.
First, list the key engineering principles that should be used to evaluate a production data pipeline. Then evaluate this pipeline using only those principles. - Daily ETL job pulls from three source systems into a staging database - Transformation logic runs as SQL stored procedures - Final tables are loaded into the analytics warehouse at 6 AM - A monitoring dashboard shows job completion status
Relevant principles: 1. Idempotency: re-running the pipeline should produce the same result, not duplicate or corrupt data. 2. Observability: failures should be detected, diagnosed, and alerted on, not just shown on a dashboard. 3. Data validation: output data should be checked against expectations before being served downstream. 4. Failure isolation: one source system failing should not block or corrupt the others. 5. Schema evolution: the pipeline should handle changes in source schema without silent data loss. Evaluation: Idempotency: Not addressed. If the ETL job fails mid-run and is restarted, it may produce duplicates or partial loads. Stored procedures that INSERT without UPSERT logic are a common source of non-idempotent behavior. Observability: Partially addressed. A completion dashboard shows whether the job ran, but not whether the data is correct. There is no mention of alerting for late or failed runs, or for row-count anomalies. Data validation: Not addressed. No quality checks between staging and warehouse. If a source system sends zero rows or a schema change drops a column, the pipeline would load bad data silently. Failure isolation: Not addressed. If one of the three source systems is unavailable, it is unclear whether the pipeline blocks entirely, loads partial data, or skips that source and continues. Schema evolution: Not addressed. SQL stored procedures are brittle to source schema changes. A column rename or type change could silently produce wrong results or fail without a clear error. Overall: The pipeline works under normal conditions but is fragile. It lacks idempotency, validation, failure isolation, and schema evolution handling — all common sources of production incidents in data pipelines.
Techniques
Concrete ways to implement Knowledge Externalization. Each technique fits a different situation.
- 01
Premise Generation
Generate knowledge and perform the task in a single prompt, binding the task to "using only those facts" so premises stay in force.
- 02
Staged Externalization
Generate knowledge in one step, then feed it as context for the task in a second step so premises can be inspected or corrected first.

Full treatment in the book
Knowledge Externalization — the complete chapter
- ▸ Mechanism — why this pattern works
- ▸ 2–4 worked examples per technique
- ▸ Placement, sequencing, and debugging rules
- ▸ Composition with related patterns